



Integration
Seamlessly integrate 50+ IT tools for complete visibility in one platform.

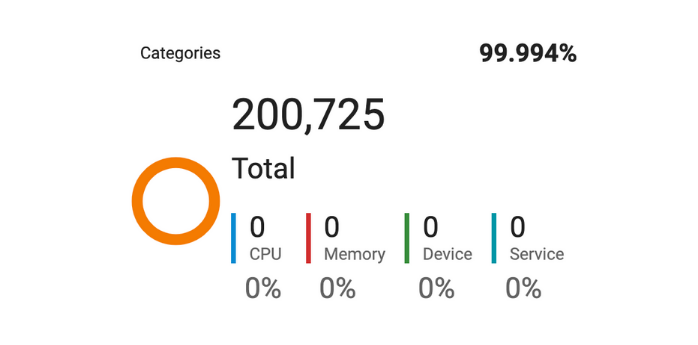
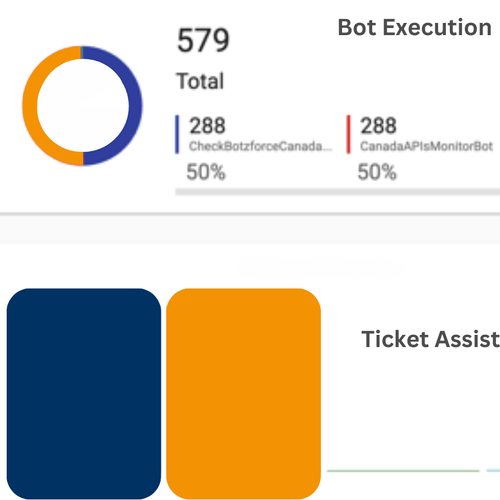
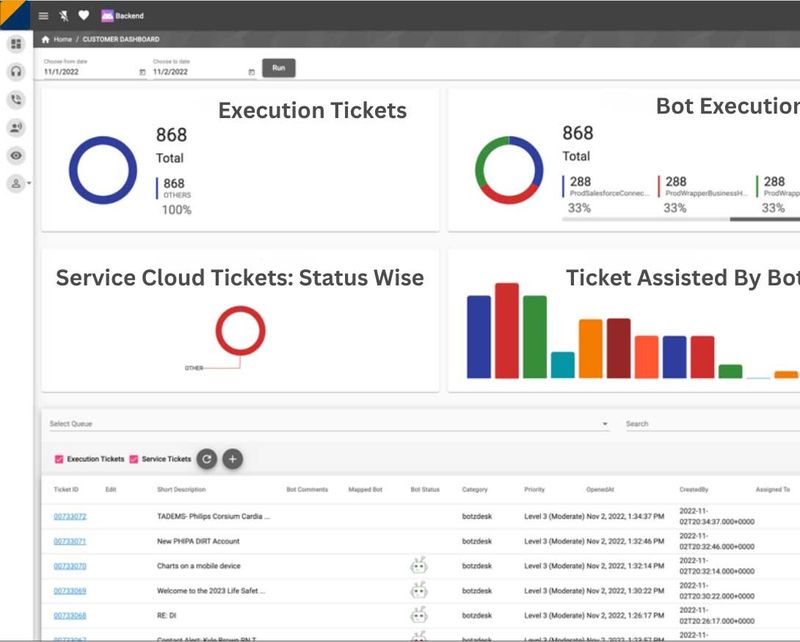
Inbuilt Analytics
Continuously optimize bot performance with our built-in, real-time analytics.

Auto Remediation
Enhance remediation actions with Botzforce AI, our low-code platform.

Creating Intelligent, Agile, and Automated Enterprises
with Botzforce, our Low-Code AI Platform
Botforze enables enterprises to continuously automate business processes and operations effortlessly.






